关于FFmpeg-python
FFmpeg是一套强大的视频、音频处理程序,也是很多视频处理软件的基础 。但是FFmpeg的命令行使用起来有一定的学习成本。而ffmpeg-python就是解决FFmpeg学习成本的问题,让开发者使用python就可以调用FFmpeg的功能,既减少了学习成本,也增加了代码的可读性。

快速开始
水平翻转视频:
import ffmpeg
stream = ffmpeg.input('input.mp4')
stream = ffmpeg.hflip(stream)
stream = ffmpeg.output(stream, 'output.mp4')
ffmpeg.run(stream)或者,如果您更喜欢流畅的界面:
import ffmpeg
(
ffmpeg
.input('input.mp4')
.hflip()
.output('output.mp4')
.run()
)安装
安装ffmpeg-python
ffmpeg-python可以通过典型的 pip 安装获取最新版本(注意:是ffmpeg-python,不要写成了python-ffmpeg):
pip install ffmpeg-python或者可以从本地克隆和安装源:
git clone git@github.com:kkroening/ffmpeg-python.git
pip install -e ./ffmpeg-python安装FFmpeg
使用该库,需要自行安装FFmpeg,如果电脑已经安装了,可以忽略本步骤。这里推荐直接使用conda进行安装,可以省下很多麻烦,其他的安装方式自行百度。
conda install ffmpeg自定义过滤器
没有看到您要查找的过滤器?虽然 ffmpeg-python包含一些最常用过滤器(例如 concat)的简写符号,但所有过滤器都可以通过 .filter运算符引用:
stream = ffmpeg.input('dummy.mp4')
stream = ffmpeg.filter(stream, 'fps', fps=25, round='up')
stream = ffmpeg.output(stream, 'dummy2.mp4')
ffmpeg.run(stream)或流利地:
(
ffmpeg
.input('dummy.mp4')
.filter('fps', fps=25, round='up')
.output('dummy2.mp4')
.run()
)特殊选项名称:
具有特殊名称的参数,例如-qscale:v(可变比特率)、-b:v(恒定比特率)等,可以指定为关键字参数字典,如下所示:
(
ffmpeg
.input('in.mp4')
.output('out.mp4', **{'qscale:v': 3})
.run()
)多个输入:
接受多个输入流的过滤器可以通过将输入流作为数组传递给ffmpeg.filter:
main = ffmpeg.input('main.mp4')
logo = ffmpeg.input('logo.png')
(
ffmpeg
.filter([main, logo], 'overlay', 10, 10)
.output('out.mp4')
.run()
)多个输出:
产生多个输出的过滤器可用于.filter_multi_output:
split = (
ffmpeg
.input('in.mp4')
.filter_multi_output('split') # 或 `.split()`
)
(
ffmpeg
.concat(split[0], split[1].reverse())
.output('out.mp4')
.run()
)(在这种特殊情况下,.split()是等效的简写,但一般方法适用于其他多输出过滤器)
字符串表达式:
ffmpeg 解释的表达式可以作为字符串参数包含并引用任何特殊的 ffmpeg 变量名称:
(
ffmpeg
.input('in.mp4')
.filter('crop', 'in_w-2*10', 'in_h-2*20')
.input('out.mp4')
)案例
获取视频信息 (ffprobe)
probe = ffmpeg.probe(args.in_filename)
video_stream = next((stream for stream in probe['streams'] if stream['codec_type'] == 'video'), None)
width = int(video_stream['width'])
height = int(video_stream['height'])为视频生成缩略图

(
ffmpeg
.input(in_filename, ss=time)
.filter('scale', width, -1)
.output(out_filename, vframes=1)
.run()
)将视频转换为 numpy 数组
out, _ = (
ffmpeg
.input('in.mp4')
.output('pipe:', format='rawvideo', pix_fmt='rgb24')
.run(capture_stdout=True)
)
video = (
np
.frombuffer(out, np.uint8)
.reshape([-1, height, width, 3])
)通过管道将单个视频帧读取为 jpeg

out, _ = (
ffmpeg
.input(in_filename)
.filter('select', 'gte(n,{})'.format(frame_num))
.output('pipe:', vframes=1, format='image2', vcodec='mjpeg')
.run(capture_stdout=True)
)将声音转换为原始 PCM 音频
out, _ = (ffmpeg
.input(in_filename, **input_kwargs)
.output('-', format='s16le', acodec='pcm_s16le', ac=1, ar='16k')
.overwrite_output()
.run(capture_stdout=True)
)从帧序列组装视频
(
ffmpeg
.input('/path/to/jpegs/*.jpg', pattern_type='glob', framerate=25)
.output('movie.mp4')
.run()
)使用额外的过滤:

(
ffmpeg
.input('/path/to/jpegs/*.jpg', pattern_type='glob', framerate=25)
.filter('deflicker', mode='pm', size=10)
.filter('scale', size='hd1080', force_original_aspect_ratio='increase')
.output('movie.mp4', crf=20, preset='slower', movflags='faststart', pix_fmt='yuv420p')
.view(filename='filter_graph')
.run()
)音频/视频管道
in1 = ffmpeg.input('in1.mp4')
in2 = ffmpeg.input('in2.mp4')
v1 = in1.video.hflip()
a1 = in1.audio
v2 = in2.video.filter('reverse').filter('hue', s=0)
a2 = in2.audio.filter('areverse').filter('aphaser')
joined = ffmpeg.concat(v1, a1, v2, a2, v=1, a=1).node
v3 = joined[0]
a3 = joined[1].filter('volume', 0.8)
out = ffmpeg.output(v3, a3, 'out.mp4')
out.run()带有偏移和视频的单声道到立体声

audio_left = (
ffmpeg
.input('audio-left.wav')
.filter('atrim', start=5)
.filter('asetpts', 'PTS-STARTPTS')
)
audio_right = (
ffmpeg
.input('audio-right.wav')
.filter('atrim', start=10)
.filter('asetpts', 'PTS-STARTPTS')
)
input_video = ffmpeg.input('input-video.mp4')
(
ffmpeg
.filter((audio_left, audio_right), 'join', inputs=2, channel_layout='stereo')
.output(input_video.video, 'output-video.mp4', shortest=None, vcodec='copy')
.overwrite_output()
.run()
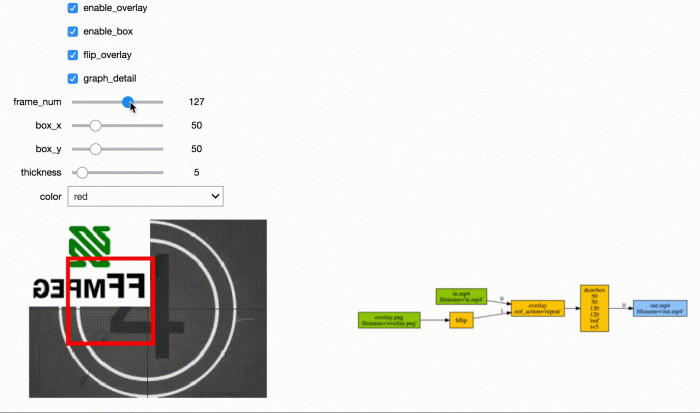
)Jupyter 帧查看器
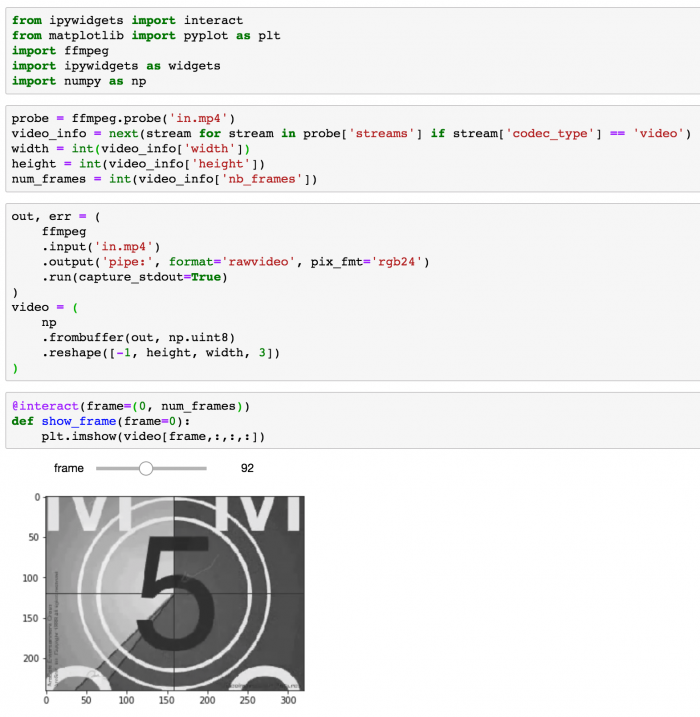
Jupyter 流编辑器
TensorFlow 流式传输
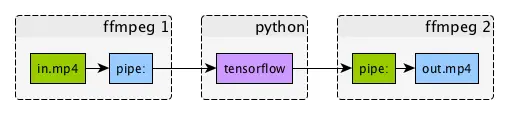
- 使用 ffmpeg 解码输入视频
- 使用“深度梦想”示例使用 tensorflow 处理视频
- 使用 ffmpeg 编码输出视频
process1 = (
ffmpeg
.input(in_filename)
.output('pipe:', format='rawvideo', pix_fmt='rgb24', vframes=8)
.run_async(pipe_stdout=True)
)
process2 = (
ffmpeg
.input('pipe:', format='rawvideo', pix_fmt='rgb24', s='{}x{}'.format(width, height))
.output(out_filename, pix_fmt='yuv420p')
.overwrite_output()
.run_async(pipe_stdin=True)
)
while True:
in_bytes = process1.stdout.read(width * height * 3)
if not in_bytes:
break
in_frame = (
np
.frombuffer(in_bytes, np.uint8)
.reshape([height, width, 3])
)
# 见例子/tensorflow_stream.py:
out_frame = deep_dream.process_frame(in_frame)
process2.stdin.write(
out_frame
.astype(np.uint8)
.tobytes()
)
process2.stdin.close()
process1.wait()
process2.wait()
FaceTime 网络摄像头输入 (OS X)
(
ffmpeg
.input('FaceTime', format='avfoundation', pix_fmt='uyvy422', framerate=30)
.output('out.mp4', pix_fmt='yuv420p', vframes=100)
.run()
)从本地视频流式传输到 HTTP 服务器
video_format = "flv"
server_url = "http://127.0.0.1:8080"
process = (
ffmpeg
.input("input.mp4")
.output(
server_url,
codec = "copy", # 使用与原始视频相同的编解码器
listen=1, # 启用 HTTP 服务器
f=video_format)
.global_args("-re") # 参数充当直播流
.run()
)要接收视频,您可以在终端中使用 ffplay:
$ ffplay -f flv http://localhost:8080从 RTSP 服务器流式传输到 TCP 套接字
packet_size = 4096
process = (
ffmpeg
.input('rtsp://%s:8554/default')
.output('-', format='h264')
.run_async(pipe_stdout=True)
)
while process.poll() is None:
packet = process.stdout.read(packet_size)
try:
tcp_socket.send(packet)
except socket.error:
process.stdout.close()
process.wait()
break