如果你会 Python,平常又频繁使用 Excel 处理数据,做很多重复性的工作,那么我强烈建议你学会使用 Python 处理 Excel 数据。
我们来看一个完整的 Excel 使用场景。
下面的 Excel 表格是一个成绩单。
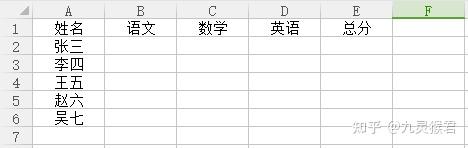
我们的任务是:
1、将成绩统计填写入表格的相应位置(用随机数代替);
2、计算每个人的总分;
3、添加”是否合格“列,总分超过或者等于200的学生,此项为”合格“,否则空白;
4、筛选出合格学生的姓名名单。
相信你使用 Excel 可以很快完成上面的操作,接下来介绍如何使用 Python 完成上述任务。
使用 Python 操作方法如下。
1、导入模块,读取表格
整个过程我们需要使用的模块是 pandas,在此之前需要安装完成。
读取表格,也就是将 Excel 表格数据转换为 Python 程序中的数据,可以使用 pandas 中的 read_excel() 函数。
返回的 sheet 就是数据表。
import pandas as pd
sheet = pd.read_excel("my_data.xlsx")
2、使用随机数填充成绩
数据表自带的 loc 非常有,从字面意思理解就是定位 location 的意思。
它有很多使用的方法,下面是一个常见的使用方式,使用中括号提供给它单元格的位置,即可定位该单元格。
我们使用循环嵌套的方式定位所有需要赋值的单元格,填入50-99之间的随机整数数据。
from random import randint
for x in range(5):
for subject in ["语文", "数学", "英语"]:
sheet.loc[x, subject] = randint(50, 100)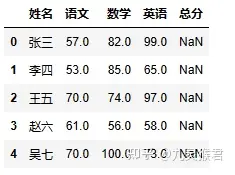
3、计算总分
这部分对于批量计算非常便捷,每一列可以作为运算数据直接参与运算,用起来简直太舒服了。
sheet["总分"] = sheet["语文"] + sheet["数学"] + sheet["英语"]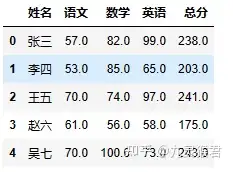
4、添加新列
添加新列的方法比较简单,下面的使用了列表生成式直接将空字符串填入新添加的列中。
sheet["是否合格"] = ["" for x in range(5)]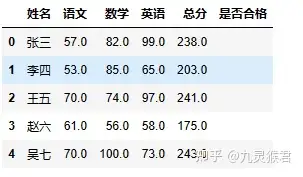
5、根据成绩判断等级。
这部分其实是在做筛选赋值,使用 loc 筛选出每一行中”总分“大于等于200的行,将其”是否合格“项赋值为”合格“。
sheet.loc[sheet["总分"] >= 200, "是否合格" ] = "合格"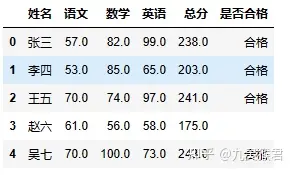
6、筛选数据。
同上,筛选出”是否合格“项为”合格“的行,并获取其姓名列。
sheet.loc[sheet["是否合格"] == "合格", "姓名"]
>>>
0 张三
1 李四
2 王五
4 吴七7、保存或者另存
使用sheet表的 to_excel() 方法可以输出数据为 Excel 表格,如果后面的文件名称与原文件相同,则覆盖,如不同则会生成另一个新的 Excel 表格。
sheet.to_excel("my_data.xlsx")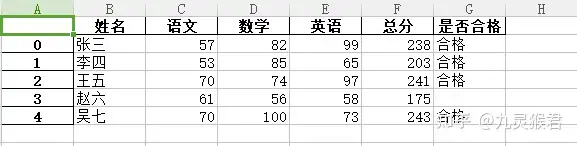
我们对以上过程做一下总结。
使用 read_excel() 函数导入 Excel 表格数据;使用 loc() 函数定位单元格用来修改或者筛选数据;使用 sheet[“列名称”] 的方式获取列参与运算以及增加列;使用 to_excel() 函数保存或者输出数据为 Excel 表格;
目前这几步操作基本涵盖了平常对于 Excel 的常规操作。
目前有三名同学共同汇总学生成绩,第二名同学完成了第二部分学生的成绩,第三名同学完成了所有同学的计算机成绩,我们要将所有成绩表和当前数据汇总在一起,然后根据总成绩排序,并且分别输出总成绩排名和各科成绩排名。
先用之前相同的方式创建第二名同学的统计表 my_data_2.xlsx。
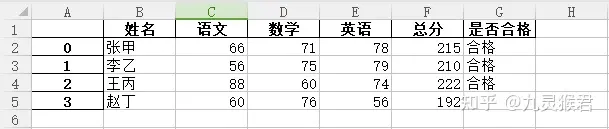
创建第三名同学的统计表 my_data_3.xlsx。
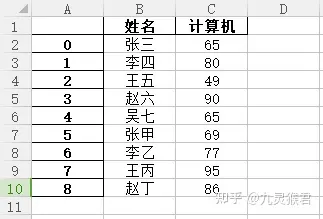
导入该数据表到程序中。
sheet1 = pd.read_excel("my_data2.xlsx")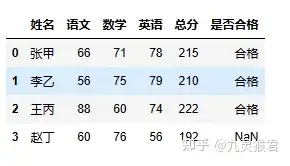
合并这两个数据表可以使用 pandas 的 merge 方法。
sheet = pd.merge(sheet1, sheet2, how="outer")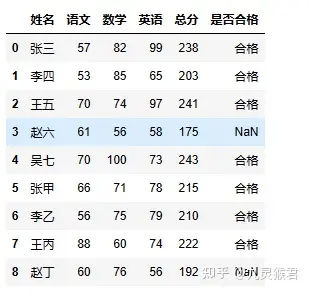
导入第三个同学的统计的成绩表。
sheet3 = pd.read_excel("my_data_3.xlsx")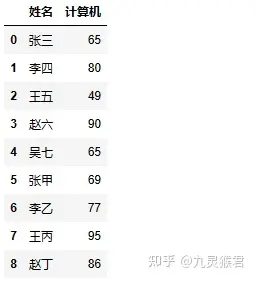
使用相同的方法合并到 sheet 表中。
sheet = pd.merge(sheet, sheet3, how="outer")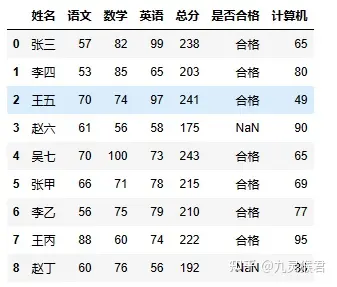
合并后,很明显计算机列的位置需要调整到靠前的位置,总分也需要更新,并且暂时不需要输出 是否合格 项。
如何完成呢?通过传入需要的项目列表完成数据列的相关调整。
sheet = sheet[["姓名","语文","数学","英语","计算机","总分"]]
sheet["总分"] = sheet["语文"] + sheet["数学"] + sheet["英语"] + sheet["计算机"]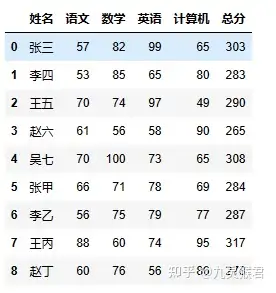
排序的过程可以使用 sheet 的 sort_values() 方法,通过 by 参数传入指定列的列名即可。ascending 参数值若为 True 则为升序排列。
reset_index() 是为了重置排序后的索引值。
sheet = sheet.sort_values(by="总分", ascending=False)
sheet = sheet.reset_index(drop=True)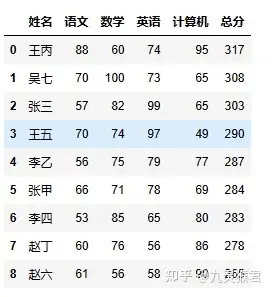
同理,各科成绩只需要按照不同列的列名排序,输出即可。
sheet.sort_values(by="语文", ascending=False)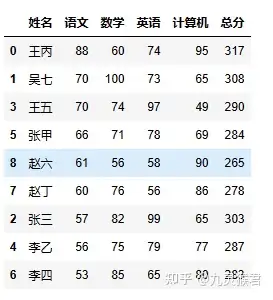
在此对上面的过程做一下总结:
可以使用 merge() 方法完成两个数据表的合并;可以使用 sort_values() 方法完成数据表排序,配合 reset_index() 可以完成索引重置。