正文
“数字音频”一词与“数字视频”一词相比,它是一种处理和显示移动图像的技术,而音频则与声音有关。数字音频是一种技术,用于捕获、记录、编辑、编码和复制声音,这些声音通常由脉冲编码调制(PCM)进行编码。FFmpeg支持许多音频格式,包括AAC、MP3、Vorbis、WAV、WMA等。FFmpeg中所有的音频格式都在第二章中列出。
关于数字音频的介绍
由耳朵感知的声音可分为音调和噪音,音调是由不规则振动产生的常规物质振动和噪音产生的。 机械振动以鼓膜感知的压力波的形式传递到听觉系统,并转换为神经信号。
音频量化和采样
由于人类听觉系统的生理限制,压力波的连续值可以用有限的一系列值代替,这些值可以作为数字存储在计算机文件中。 计算机使用二进制数字,所以常见的音频位深度(音频分辨率)是两个幂:

| 位深度 | 值计算 | 描述 |
|---|---|---|
| 8 bit | 2^8 =256 | 用于电话,旧设备 |
| 12 bit | 2^12 =4,096 | DV(数字视频)的标准,用于数码相机等 |
| 14 bit | 2^14 =16,384 | 用于NICAM压缩,电视立体声,等等 |
| 16 bit | 2^16 =65,536 | 标准音频CD和DAT(数字音频磁带),是当今最常见的 |
| 20 bit | 2^20 =1,048,576 | 附加标准的超级音频CD和DVD音频 |
| 24 bit | 2^24 =16,777,216 | 标准的超级音频CD和DVD音频 |
| 32 bit | 2^32 =4,294,967,296 | 专业设备,蓝光技术 |
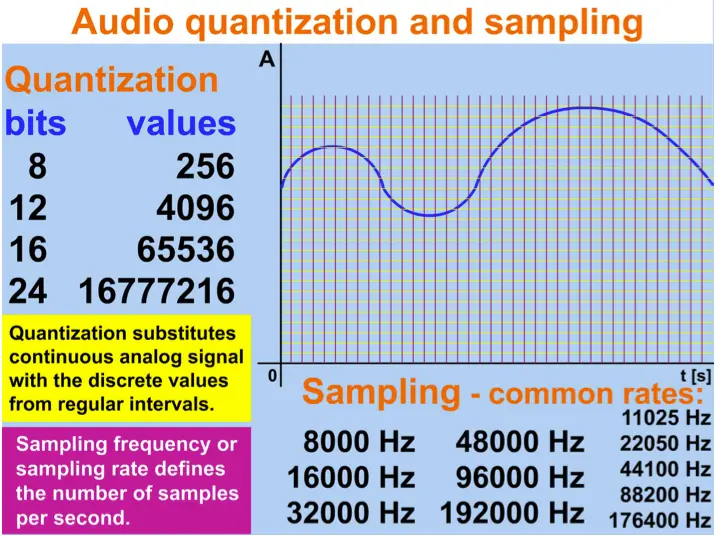
模拟音频信号(大组数值)通过在每个时间单位创建一组较小的采样数字化,常见采样频率(采样率)在表中描述:

| 8000 Hz | 用于电话、无线网络和麦克风等 |
|---|---|
| 11025 Hz | 用于低质量PCM和MPEG音频等 |
| 16000 Hz | 电话宽带(2倍8000 Hz),用于VOIP设备等 |
| 22050 Hz | 用于低质量PCM和MPEG音频等 |
| 32000 Hz | 用于DAT, NICAM,迷你DV相机,无线麦克风等 |
| 44100 Hz | 音频CD标准,用于MPEG-1, PAL电视等 |
| 48000 Hz | 专业使用标准费率,为消费者提供DV、DVD、数字电视等 |
| 96000 Hz | 标准的DVD-音频,蓝光光盘,HD DVD等 |
| 192000 Hz | 用于DVD-音频,蓝光光盘,HD DVD,专业设备 |
| 352800 Hz | 数字极端定义,用于超级音频光盘 |
音频文件格式
量化和采样音频被保存在不同的媒体文件格式,下一个表描述特定的文件格式,仅用于音频(MP3格式支持也包括图像):

| 未压缩的 | 无损压缩 | 有损压缩 |
|---|---|---|
| ALAC | AIFF (PCM) | AAC |
| AU | ALS | AC-3 |
| BWF | ATRAC | AMR |
| PCM (raw, without header) | FLAC | MP2, MP3 |
| WAV (PCM) | WavPack | Musepack |
| WMA | Speex | |
| Vorbis (OGG) |
声音合成
声音是由在固定位置振动的物体的振动而产生的,规则的振动被称为音调,可以用不同振幅和频率的正弦和余弦波来表示。
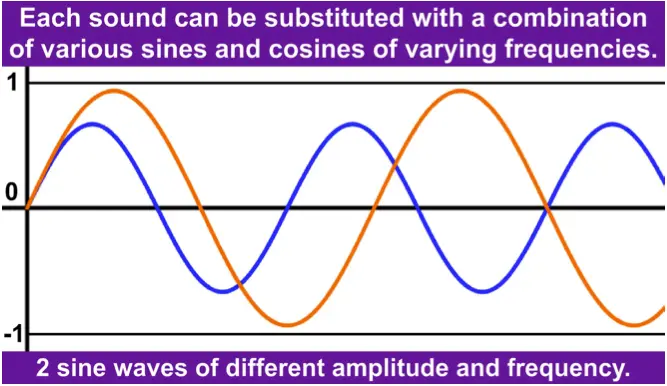
用一个表达式sin(tone_height2PI*t)来创建一定高度的连续色调,在Hz中,tone_height为给定频率,PI是一个数学常量,t是在秒内指定时间的变量。为了用数学表达式创建声音,我们可以使用音频源aevalsrc,它的输出可以作为音频文件保存。输出声音可以包含多个通道,每个通道由一个带有三个可能变量的表达式指定,详细信息在表中:

| 描述 | 创建一个由一个(mono)、两个(立体声)或更多表达式指定的音频信号 |
|---|---|
| 语法 | aevalsrc=exprs[::options] exprs:是一个冒号分隔的表达式列表,每个新表达式都指定了新通道 options:键=值对的冒号分隔列表 |
| 表达式exprs中可用变量的描述 | |
| n | 评估样本的数量,从0开始 |
| t | 以秒为单位的时间,从0开始 |
| s | 采样率 |
| 可用选项的描述 | |
| c or channel_layout | 通道布局,通道数量必须等于表达式的数量 |
| d or duration | max。持续时间,如果没有指定,或者是负数,音频将生成直到程序停止 |
| n or nb_samples | 每个通道每个输出帧的样本数量,默认为1024个样本 |
| s or sample_rate | 采样率,默认值为44100 Hz |
根据音符A4的音调标准,下一个表格包含从C1到B8的音调频率,频率为440 Hz。 人声范围从E2(男低音)到C6(女高音)。
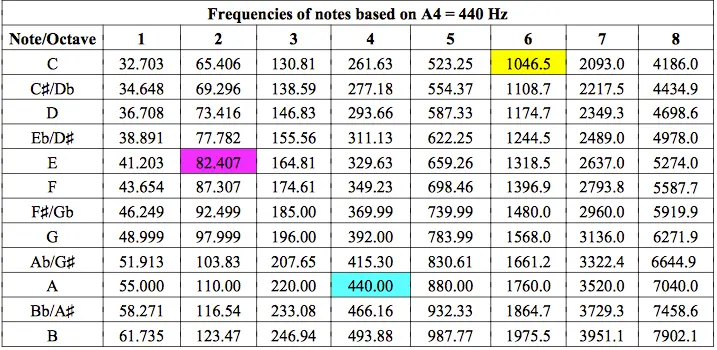
为了产生音符A4,音高的调优标准,我们可以将tone_height设置为440 Hz:
ffmpeg -f lavfi -i aevalsrc=sin(440*2*PI*t) -t 10 noteA4.mp3
我的测试命令是:
ffmpeg -f lavfi -i aevalsrc=sin\(440*2*PI*t\) -t 10 /Users/zhangfangtao/Desktop/001.mp3
*显示结果生成一个10秒钟的音频文件。
立体声和更复杂的声音
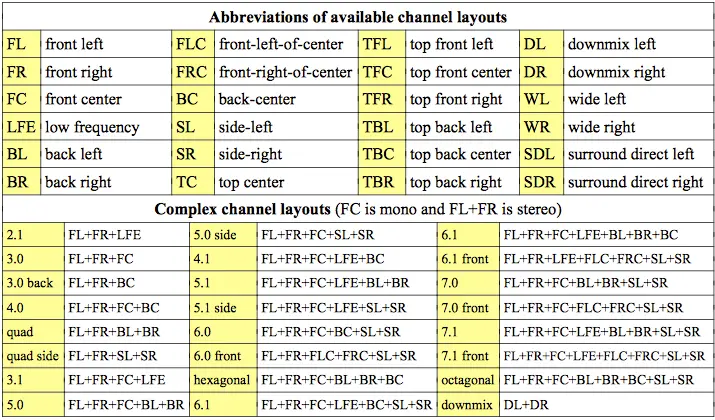
要使用aevalsrc音频源创建多声道声音,我们为每个声道指定一个定义表达式,声道由冒号分隔,然后在双冒号后指定其定位。 表格中描述了可以使用-layout选项显示的可用通道布局:
例如,在左边的通道中创建C4音调,在右边的C5音调中,我们可以使用命令:
ffplay -f lavfi -i aevalsrc=sin(261.63*2*PI*t):cos(523.25*2*PI*t)::c=FL+FR
我的电脑上上面的命令会报错,我使用的测试命令如下;
ffplay -f lavfi -i aevalsrc=sin\(261.63*2*PI*t\)|cos\(523.25*2*PI*t\)::c=FL+FR
减轻压力的双耳音调
立体声的特殊类型是双耳音(节拍) – 两个频率差约30Hz或更小的音,两个音的频率必须低于1000Hz。 使用立体声耳机收听双耳音可以为听众带来积极的影响,如减轻压力,提高学习能力和对大脑功能产生的其他积极影响,但结果因使用的频率基准和频率差异而有所不同。 要在基频为500 Hz时以10 Hz的差异创建双耳节拍,我们会指定具有略微不同声道的立体声:
ffplay -f lavfi -i aevalsrc=sin(495*2*PI*t):sin(505*2*PI*t)::c=FL+FR
我的测试命令:
ffplay -f lavfi -i aevalsrc=sin\(495*2*PI*t\)|sin\(505*2*PI*t\)::c=FL+FR
音量设置
声音音量应该仔细调整,以保护我们的耳朵和ffmpeg提供2种方法。第一个使用-vol选项,它接受从0到256的整数值,其中256是最大值,例如:
ffmpeg -i sound.wav -vol 180 sound_middle_loud.wav
我的测试命令
ffmpeg -i /Users/zhangfangtao/Desktop/DYZDJ.mp3 -vol 128 /Users/zhangfangtao/Desktop/DYZDJ3.mp3
另一种方法是使用表中描述的卷过滤器:

| 描述 | 将输入音频卷更改为指定的值 |
|---|---|
| 语法 | volume=vol |
| vol的描述参数 | |
| vol | 参数vol是一个表达式,其值可以通过以下两种方式来指定: 1.作为一个小数,那么output_volume = vol * input_volume 2.作为一个十进制数与dB后缀,然后output_volume = 10 ^(卷/ 20)* input_volume |
例如,将音量降低到三分之二,我们可以使用以下命令:
ffmpeg -i music.wav -af volume=2/3 quiet_music.wav
我的测试命令:
ffmpeg -i /Users/zhangfangtao/Desktop/DYZDJ.mp3 -af volume=1/3 /Users/zhangfangtao/Desktop/DYZDJ4.mp3
为了增加10分贝的音量,我们可以使用以下命令:
ffmpeg -i sound.aac -af volume=10dB louder_sound.aac
我的测试命令:
ffmpeg -i /Users/zhangfangtao/Desktop/DYZDJ.mp3 -af volume=20dB /Users/zhangfangtao/Desktop/DYZDJ5.mp3
多个声音混合到一个输出
为了混合不同长度的声音并指定一个过渡段,我们可以使用amix过滤器。

| 描述 | 音频混频器,从多个音频输入中创建一个指定持续时间的输出,输入中断持续时间——可以指定输入之间的转换时间 |
|---|---|
| 语法 | amix=inputs=ins[:duration=dur[:dropout_transition=dt]] |
| 参数描述 | |
| inputs | 输入的数量,默认值是2。 |
| duration | 指定如何确定流的结束,可用选项为(下面对应着序列号是0~2): 1.最长持续时间最长的输入,默认值 2.最短时间的最短输入 3.第一次输入的持续时长 |
| dropout_transition | 当输入流结束时,用于进行卷重正化的转换时,默认值为2 |
例如,下一个命令将4个输入音频文件混合到一个,它的持续时间与最长输入的持续时间相同,而特定声音输入之间的转换是5秒:
ffmpeg -i sound1.wav -i sound2.wav -i sound3.wav -i sound4.wav ^ -filter_complex amix=inputs=4:dropout_transition=5 sounds.wav
我的测试命令:
ffmpeg -i /Users/zhangfangtao/Desktop/DYZDJ.mp3 -i /Users/zhangfangtao/Desktop/NWDSL.mp3 -filter_complex amix=inputs=2:dropout_transition=5 /Users/zhangfangtao/Desktop/NWDSL2.mp3
- 结果是生成了一个新的音乐文件,时长是这两个里面最长的那个时间,而且,里面的声音也是时长比较长的那个音乐的声音,音乐信息确实前者的。
*下面的是添加了一些添加了结束时间的参数,具体的命令如下:
ffmpeg -i /Users/zhangfangtao/Desktop/DYZDJ.mp3 -i /Users/zhangfangtao/Desktop/NWDSL.mp3 -filter_complex amix=inputs=2:duration=0:dropout_transition=5 /Users/zhangfangtao/Desktop/NWDSL2.mp3
- 结果表明:duration可选范围是0,1,2,不过只有当我把参数结果设置成0的时候才会生成一个有最长时长的音频文件,其他的参数类型情况下生成的音乐长度都是0.
将立体声调至单声道,环绕立体声
要将立体声声音缩混为单声道声音,我们可以使用表格中所述的平移滤波器:

| 描述 | 根据输入的通道布局混合具有特定增益级别的通道,接着是一组通道定义。 典型用途是将立体声改为单声道,将5 + 1声道改为立体声等。声像滤波器还可以重新映射音频流的声道。 |
|---|---|
| 语法 | pan=layout:channel_def[:channel_def[:channel_def…]] |
| 主要参数 | |
| layout | 输出通道布局或通道数 |
| channel_def | 通道定义的形式:ch_name = [gain *] in_name [+ [gain *] in_name …] |
| 通道定义参数 | |
| ch_name | 通道定义,通道名称(FL, FR,等等)或通道数(c0, c1,等等) |
| gain | 通道的乘法系数,值1保持体积不变 |
| in_name | 输入通道使用,指定与ch_name相同的方式,不要混合命名和编号的输入通道 |
下面的几个例子将立体音响与单声道的声音联系在一起:
- 左右通道和相同的音量混合在一起。
ffmpeg -i stereo.wav -af pan=1:c0=0.5*c0+0.5*c1 mono.wav
我的测试命令:
ffmpeg -i /Users/zhangfangtao/Desktop/NWDSL.mp3 -af pan=1|c0=0.5*c0+0.5*c1 /Users/zhangfangtao/Desktop/NWDSL2.mp3
- 结果是,生成了一个0kb的音乐文件,原因是这个歌曲是单声道的,没有设置的意义
或者使用下面简单的方式:
ffmpeg -i stereo.wav -af pan=mono mono.wav
ffmpeg -i stereo.wav -af pan=1 mono.wav
*左通道与更大的音量混合,而不是正确的通道
ffmpeg -i stereo.wav -af pan=1:c0=0.6*c0+0.4*c1 mono.wav
- 右通道与比左通道更大的音量混合
ffmpeg -i stereo.wav -af pan=1:c0=0.7*c0+0.3*c1 mono.wav
一个简单的方法,没有过滤器,如何将多通道音频与超过2个通道混合使用,使用-ac[:stream_specifier]选项,该选项包含一个整数参数,该参数指定输出通道的数量:
ffmpeg -i 5_1_surround_sound.wav -ac 2 stereo.wav
为了指定其他的参数,比如一个特定通道的增益,我们使用pan过滤器。下一个例子自动减少到立体声,3,4,5或7频道的多通道音频:
ffmpeg -i surround.wav -af pan=stereo:^ FL<FL+0.5*FC+0.6*BL+0.6*SL:FR<FR+0.5*FC+0.6*BR+0.6*SR stereo.wav
简单的音频分析仪
每个输入音频帧的详细信息由一个ashowinfo过滤器提供,该过滤器输出10个不同的参数,每一个音频帧,并在表中描述。

| 描述 | 显示每个输入音频帧的一行,其中包含组织到键=值对的参数信息 |
|---|---|
| 语法 | -af ashowinfo |
| 描述生成的参数 | |
| n | 帧的序号,从0开始 |
| pts | 表示时间戳的输入框,表示为若干时间单位 |
| pts_time | 输入框的表示时间戳,表示为若干秒 |
| pos | 输入流中的帧位置,值-1表示该参数不可用或没有意义(例如合成音频) |
| fmt | 样本格式名称 |
| chlayout | 通道布局(mono,立体声等) |
| nb_samples | 当前帧中每个通道的采样数 |
| rate | 音频帧采样率 |
| checksum | 输入帧中所有飞机的Adler-32校验和的十六进制值 |
| plane_checksum | 每个输入帧平面的Adler-32校验和的十六进制值,在形式中表示[c0 c1 c2 c3 c5 c6 c7] |
因为ashowinfo输出可以很长,所以应该用-report选项保存到文件中。
ffmpeg -report -i audio.wav -af ashowinfo -f null /dev/null
在44100 Hz中编码10秒的立体声音频的结果,s16在图片中说明:
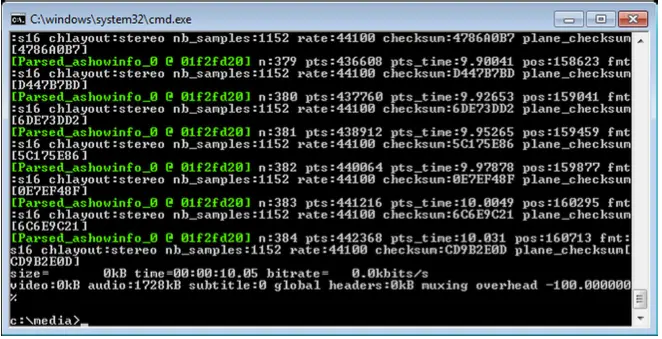
我的测试命令:
ffmpeg -report -i /Users/zhangfangtao/Desktop/NWDSL.mp3 -af ashowinfo -f null /Users/zhangfangtao/Desktop/null
- 效果图:

调整耳机听音
为了增加输入音频文件的立体声效果,我们可以使用表格中描述的耳垢过滤器:

| 描述 | 将立体图像的位置从内部(耳机的标准)改变到外部和听众的前方(比如扬声器)。它使用CD音频(44,1 kHz频率),它插入特殊的提示 |
|---|---|
| 语法 | -af earwax |
例如,在.mp3文件音乐中扩大音频的立体声效果,我们可以使用以下命令:
ffmpeg -i music.mp3 -af earwax -q 1 music_headphones.mp3
我的测试命令如下:
ffmpeg -i /Users/zhangfangtao/Desktop/NWDSL.mp3 -af earwax -q 1 /Users/zhangfangtao/Desktop/NWDSL2.mp3
- 结果就是生成了一个立体声效果更加显著的音乐。。。。听起来确实很明显
使用-map_channel选项进行音频修改
-map_channel选项可以更改各种音频参数,其语法为:
-map_channel [in_file_id.stream_spec.channel_id|-1][:out_file_id.stream_spec]
- 如果
out_file_id。stream_spec参数没有设置,音频通道被映射到所有音频流上 - 如果使用“-1”而不是
in_file_id.stream_spec。channel_id,映射是一个静音通道 -map_channel选项的顺序决定了输出流中通道的顺序,输出通道的布局是从映射的通道数计算出来的(如果使用了一个-map_channel选项,如果使用了两个-map_channel选项,等等)- 如果输入和输出通道布局不匹配(例如两个
“-map_channel”选项和“-ac 6”),与-map_channel组合使用的-ac选项将使通道增益级别得到更新
在立体声输入中切换音频通道
若要在立体声音频文件中以正确的通道交换左通道,我们可以使用以下命令:
ffmpeg -i stereo.mp3 -map_channel 0.0.1 -map_channel 0.0.0 ch_switch.mp3
我的测试命令:
ffmpeg -i /Users/zhangfangtao/Desktop/NWDSL.mp3 -map 0:0 -map_channel 0.0.0:0.0 -map_channel 0.0.1:0.1 /Users/zhangfangtao/Desktop/NWDSL2.mp3
- 结果:生成了一个新的mp3音乐,左右声道换了,听不出来
将立体声声音分割成两个不同的流
将立体声输入的2个通道分成2个不同的流,编码为1个输出文件,我们使用命令(MP3只能包含1个音频流,因此输出格式必须是AAC、OGG、WAV等):
ffmpeg -i stereo.mp3 -map 0:0 -map 0:0 -map_channel 0.0.0:0.0 ^ -map_channel 0.0.1:0.1 output.aac
我的测试命令:
ffmpeg -i /Users/zhangfangtao/Desktop/NWDSL.mp3 -map 0:0 -map 0:0 -map_channel 0.0.0:0.0 -map_channel 0.0.1:0.1 /Users/zhangfangtao/Desktop/NWDSL2.aac
- 结果生成了一个新的aac文件,不过新的文件播放起来,像是一种慢放。。。。那种声音。。。销魂。。。
从立体声输入中调出一个频道
要从输入中关闭特定的通道,我们可以使用-map_channel选项的-1值。例如,为了使第一个通道从立体声声音中静音,我们可以使用以下命令:
ffmpeg -i stereo12.mp3 -map_channel -1 -map_channel 0.0.1 mono2.mp3
我的测试命令:
ffmpeg -i /Users/zhangfangtao/Desktop/NWDSL.mp3 -map_channel -1 -map_channel 0.0.1 /Users/zhangfangtao/Desktop/NWDSL2.mp3
- 显示的结果是:生成了一个只有右声道的音乐文件。
将两个音频流合并到一个多通道流
要将2个音频流连接到1个多通道流,我们可以使用一个有1个可选参数输入的amerge过滤器,该参数值设置输入文件的数量,默认值为2。所有输入文件都必须使用相同的采样率和文件格式进行编码。例如,将2个文件中的2个mono声音合并到一个单一的立体声流中,我们可以使用这个命令(总持续时间等于较短输入的持续时间):
ffmpeg -i mono1.mp3 -af amovie=mono2.mp3[2];[in][2]amerge stereo.mp3
音频流转发与缓冲buffet order控制。
两个音频输入的流同步可以由astreamsync过滤器控制,它有一个参数,可以由一个可选的表达式和多个变量来设置值。表达式的默认值是t2-t1(如下所示),这意味着总是以较小的时间戳转发流。

| 描述 | 转发两个音频流并控制转发缓冲区的顺序 |
|---|---|
| 语法 | astreamsync[=expr] 如果expr < 0,则将第一个流转发,否则将转发第二个流 |
| 在表达式中可以使用的变量 | |
| b1, b2 | 到现在流1和流2的缓冲区的数量 |
| s1, s2 | 到目前为止,在第1条和第2条上转发的样品数量 |
| t1, t2 | stream1和stream2的当前时间戳 |